Bitbucket
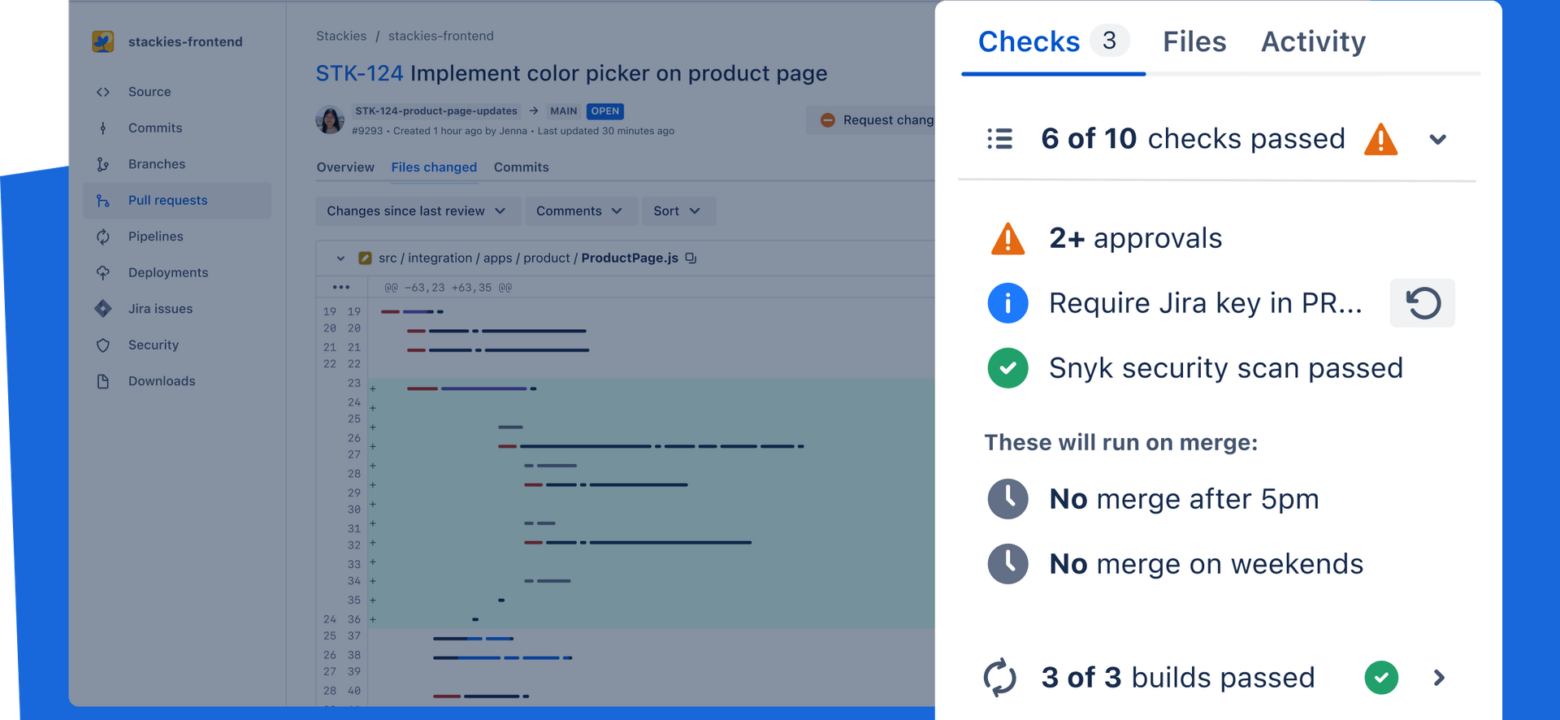
With built-in CI/CD, native security tools, integrated planning, and AI agents, Bitbucket Cloud helps organizations accelerate productivity, improve engineering standards,...

Today we are excited to be delivering the #1 requested feature in Bitbucket Cloud — draft pull requests. And to...
Overview Recently we introduced support for Failure Strategies, which allows developers to implement more powerful logic and control flow into...
We’re excited to announce the release of a new feature in Bitbucket Pipelines designed to make it easier for you...
As part of Atlassian’s ongoing investment in security, we’re introducing new controls to help administrators manage authentication tokens more effectively and...
As promised in our blog announcing support for signed commits, you can now use SSH keys to sign commits in...