
Possible speed improvement for studies per weekday charts
Issue #223
resolved
The data for the studies per weekday charts, which also drill down to studies per hour in each weekday, is calculated in view.py using a nested FOR loop:
studiesPerHourInWeekdays = [[0 for x in range(24)] for x in range(7)]
for day in range(7):
studyTimesOnThisWeekday = f.qs.filter(study_date__week_day=day+1).values('study_time')
if studyTimesOnThisWeekday:
for hour in range(24):
try:
studiesPerHourInWeekdays[day][hour] = studyTimesOnThisWeekday.filter(study_time__gte = str(hour)+':00').filter(study_time__lte = str(hour)+':59').values('study_time').count()
except:
studiesPerHourInWeekdays[day][hour] = 0
I think it should be possible to replace the inner loop, which runs 24 times for each day of the week, with a single qsstats time_series query per weekday. The results of this time_series query could then be used to populate the hourly data for that day. I strongly suspect that this will be faster than the current loop.
This isn't possible at the moment because qsstats requires input in the form of a datetime.datetime variable, and at the moment we only have separate study_date (datetime.date) and study_time (datetime.time) fields. If these two fields could be combined into a new study_datetime field using datetime.combine, and then my proposed improvement would work.
I've tried adding a new study_datetime property (calculated field) to the GeneralStudyModuleAttr table, but unfortunately the qsstats time_series has to have an actual data field, and won't work on a calculated field.
Comments (20)
-
reporter
-
reporter
This django profiler may be helpful in tracking down possible optimisations: https://github.com/mtford90/silk/
-
reporter
@edmcdonagh, what are your thoughts on adding an additional field to the database to hold a datetime object representing the combined study_date and study_time? It would make implementing my potential speedup much easier. If you're not dead against the idea, then I'll run a test to see if it really will speed things up as I expect.
-
@dplatten That would be fine, and would sort you out for new imports. For existing studies, it is possible to do a data migration along with a schema migration, though that might get complicated with the upgrade to django 1.7 and change from South to built in - or maybe it might be easy!
I guess the thing to do would be try it and see how well it works

The other thing to consider is issue #95, but don't worry about that for now

-
reporter
Added new datetime field to hold study datetime. References issue
#223.→ <<cset a498f96fffc4>>
-
reporter
@edmcdonagh, I have a manually-written data migration file that is associated with this. Where do I put it? git is ignoring it if I put it in the migrations folder.
-
When I did this for the 0.5.1 upgrade, I kept the migration file in 'stuff', then placed it manually in migrations before wrapping the code up for pypi.
I have the migrations folder as an exclude for git deliberately.
-
reporter
Added a new database field, study_datetime_time. This is a datetime field with the date forced to 1.1.1900. The time component is the study_time. The field is used in time_series queries to determine how many studies are carried out in each of the 24 hours of the day. If the field is populated with the study date as well as the study time then the hourly query doesn't work - it treats each day as a separate entity: I need all the days to be treated as one. I need to see if this new method of calculating the workload chart data offers a significant performance advantage. If it doesn't then I'll drop the idea. References issue
#223.→ <<cset 5c4e8317c9cb>>
-
reporter
Added data migration to populate new datetime field. References issue
#223.→ <<cset a2fae13f6183>>
-
reporter
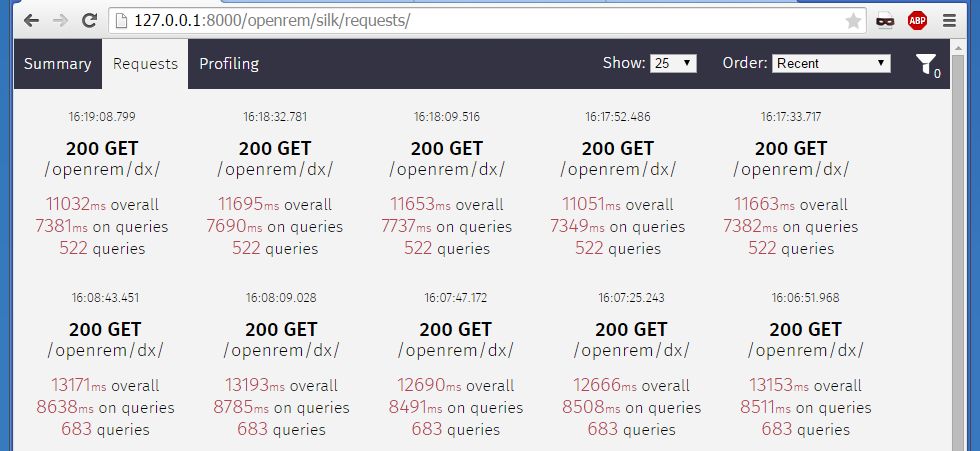
The method using the study_datetime_time field is faster. For just under 20,000 DX studies the new code is around 1 s quicker (about 12 %) for its queries. The top row of the image below is five runs of the new code; the bottom row is five runs of the old code.
There will be some Silk overhead in the timings.
I don't know how the speed differences scale with the number of studies at the moment.
-
reporter
Altered name of new field to be more descriptive. References issue
#223.→ <<cset 1407037c2b27>>
-
reporter
@edmcdonagh, this works OK, and is faster than the previous method. Do you think it's OK to include it in the develop branch now?
-
Yes, go ahead. Can you put a stub at least in the release notes about how to migrate. The release notes don't exist yet, so please create them, with a title of release-0.7.0.rst.
-
reporter
Will do, but probably not until the end of next week.
-
Added new datetime field to hold study datetime. References issue
#223.→ <<cset a498f96fffc4>>
-
Added a new database field, study_datetime_time. This is a datetime field with the date forced to 1.1.1900. The time component is the study_time. The field is used in time_series queries to determine how many studies are carried out in each of the 24 hours of the day. If the field is populated with the study date as well as the study time then the hourly query doesn't work - it treats each day as a separate entity: I need all the days to be treated as one. I need to see if this new method of calculating the workload chart data offers a significant performance advantage. If it doesn't then I'll drop the idea. References issue
#223.→ <<cset 5c4e8317c9cb>>
-
Added data migration to populate new datetime field. References issue
#223.→ <<cset a2fae13f6183>>
-
Altered name of new field to be more descriptive. References issue
#223.→ <<cset 1407037c2b27>>
-
reporter
- changed status to resolved
This has been fixed now.
-
- changed milestone to 0.7.0
- Log in to comment

I've posted a message on stackoverflow asking for advice with this: http://stackoverflow.com/questions/30141704/speed-up-django-nested-for-loop-time-series