Wiki
Clone wikineo4j-databridge / 4.4 Auto-configuring JDBC datasources
4.4 Auto-configuring JDBC datasources
If you have a JDBC datasource you want to import into the graph, Databridge can automatically create resource and schema definitions for you based on inspecting the JDBC database schema.
The JDBC datasource
In this tutorial, we'll use the sample H2 database that comes bundled in the tutorial/jdbc directory of
the Databridge installation. This database contains four tables:
- Country
- Department
- Employee
- History
These tables are connected via foreign key dependencies according to the following schema:
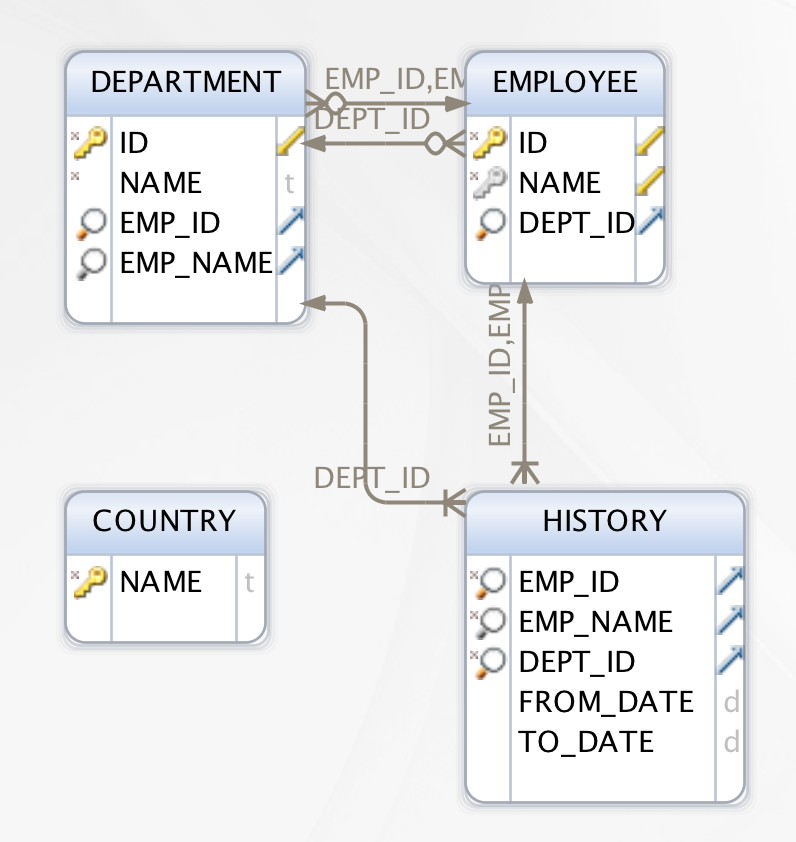
Managing foreign key dependencies
Autoconfiguration manages foreign key dependencies in the database by defining an order in which tables are extracted during the import.
Generally, tables with no foreign key dependencies are handled first, then tables that export foreign keys to other tables, then finally tables that import foreign keys.
In the event that a table both imports and exports foreign keys, autoconfiguration sets up the resource and schema definitions to break the circular dependency, and configures the individual schema files for each table to ensure that all the data is fully imported.
The overall ordering is defined in schema.json:
#!bash { "include" : [ "country_schema.json", "department_schema.json", "employee_schema.json", "history_schema.json" ] }
Join tables
Autoconfiguration uses a simple heuristic to detect records from join tables which could qualify to be configured as relationships in the graph, instead of nodes.
A table is detected as a qualifying join table if it meets the following criteria:
- it does not export a primary key or if it does, the primary key is not imported by any other table
- it imports exactly two foreign keys.
- it has fewer than 5 non-key columns.
- it does not define uniqueness constraints on any non-key columns
The History table in the above schema meets these criteria, and so its records will be imported as relationships in the graph between the relevant Employee and Department nodes, with two properties: FROM_DATE and TO_DATE.
Generating the import configuration
To automatically generate the graph schema and resource files required to import this data we use the auto shell command, passing in a name for the import and some jdbc connection details:
#!bash bin/databridge auto h2demo "jdbc:h2:file:./tutorial/jdbc/h2demo" {username} {password}
Don't forget to add the relevant JDBC driver to the lib directory of the Databridge installation
After running this command the following files will be created in import/h2demo
#!bash
import/h2demo/resources:
country_resource.json
department_resource.json
employee_resource.json
history_resource.json
import/h2demo/schema:
country_schema.json
department_schema.json
employee_schema.json
history_schema.json
schema.json
Running the autoconfigured import
Once autoconfiguration is complete, you can use the generated schema definitions directly, or you can edit them and customise them first.
Either way, running the import from an autoconfigured JDBC source is exactly the same as running a manually-configured one. In this example, we specified the import project to be called h2demo, and it was automatically installed in the default import folder in Databridge. To run the import therefore, we simply use the import command:
#!bash
bin/databridge import h2demo
Updated