Wiki
Clone wikiExperimentTool / D2 Description of Architecture
API of Brownie
In order to better understand the architecture of Brownie, use the following link to get to the API:
http://browniedocu.bitbucket.org/
The architecture of the platform
...is outlined in Figure 1. In general, the components are segmented along two dimensions: i) whether they are used at the server or on the client side, denoted within each component, and
ii) whether they are part of the built-in tier or the customizable tier, denoted on the y-axis. We proceed to explain these components in detail.
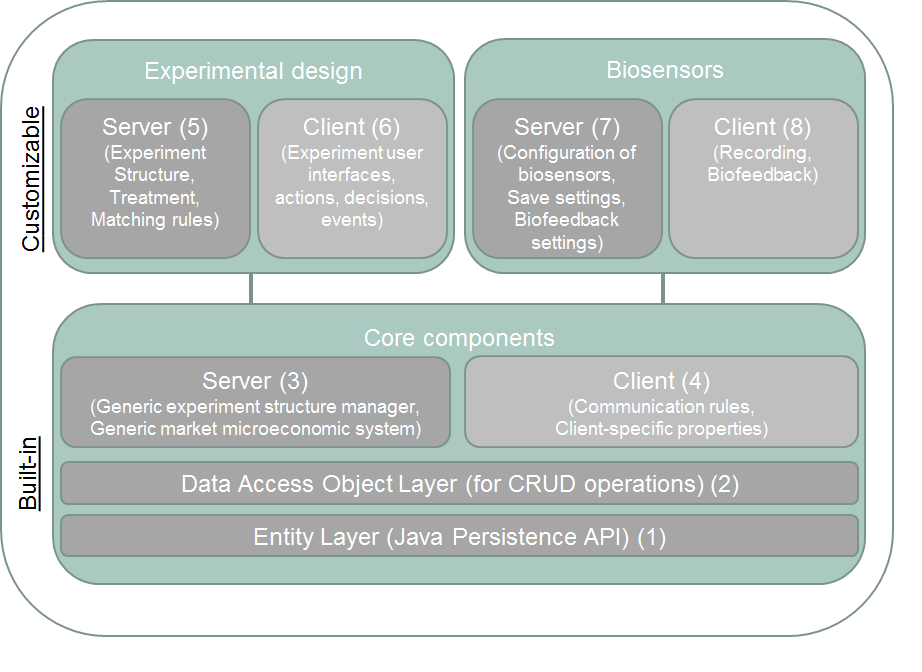
Built-in Tier
We first present the architecture of Brownie along the y-axis of Figure 1: the built-in tier, and the customizable tier of Brownie. The built-in tier is the stable core of the platform. It is ready-to-use, and requires no (or minimal) alterations while designing an experiment. The built-in tier is in turn composed of (i) the entity layer, (ii) the data access object (DAO) layer; and the components that define (iii) the generic server and (iv) the generic client. The entity layer performs the role of object relation mapping to persist Plain Old Java Objects (POJO) to a database, and it is implemented using Java Persistence API (JPA) . In addition to a relational specification that supports mapping Java objects to a database, JPA supports a rich query language which facilitates static and dynamic queries. As mentioned in the release notes of JPA, “[t]he Java Persistence API draws upon the best ideas from persistence technologies such as Hibernate, TopLink, and JDO. Customers now no longer face the choice between incompatible non-standard persistence models for object/relational mapping.” A detailed entity model and description of the table relations is provided in the wiki article entitled "Entity Layer." The corresponding project for the Entity Layer is the ExpJPA project, shown in in the wiki article entitled "Project structure."
The second layer of the built-in tier is the DAO layer, serving as an abstraction to encapsulate all access to the data source. The DAO manages the connection with the data source to obtain and store data. Hence, standard create, read, update, or delete operations are performed on the Entity Layer by means of the adapter objects in DAO layer. As can be observed in Figure 1, through the DAO, the entity layer can thus be accessed from both the client- and server- sides, i.e., by all the components above it. For instance, using the DAO objects, the server can log information about sessions to the database, while the status and decisions of each client can be directly logged by each client to the server database by means of Trial DAO objects (Wiki article : Entity Layer). The DAO layer applies the Data Access Object design pattern and is also located in the ExpJPA Project, as shown in Wiki article : Project Structure.
The built-in tier finally contains two components to manage the structure of an experiment, with the experiment structure manager and the experimental procedure on the server side (3), and the communication rules and client-specific properties on the client side (4). The experiment structure manager is invoked when the experimenter defines the flow of the experiment using Brownie’s UI. Details about the treatments (interfaces associated with the treatment), sessions (session date, cohort size, membership and matching rules), and within each session, the experiment sequence information (number of periods, pauses, etc.) can be specified from the UI. We will now explain each of these three aspects in detail.
The treatment management dialog in the UI is used to define the association between a given treatment and an experiment’s interface. Hence, this serves as the starting point for implementing new experiments. The fundamental building blocks of a generic experimental design are implemented on the server side middleware, namely: the Institution and the Environment. The institution can be used to define the experiment’s behavior, with respect to the start rules, the message rules, and end rules of the market. Variations in the experiment’s behavior across treatments can be implemented in the same Institution as well, and hence a single class can be used to define the flow across several treatments. Turning to the environment, it helps to define the primary experiment features and differences in experimental parameters across different treatments. For instance, for an experiment with two types of auctions and two levels of information granularity, there are four parameter combinations in a full-factorial design. The parameter sets for these four treatments would then be defined in the Environment class, whereas the flow of the screens in in these four treatments would be defined in the Institution class. This flow can be identical, or varied, depending on the experiment’s design. Therefore, an experiment always extends both classes, the Institution and the Environment, to define and implement the market.
From the server UI of Brownie, using the session details and the experiment sequence information stated above, in the middleware code, the session creator (SessionCreator) employs these building blocks to create and initiate a session. The corresponding project for the Server side layer is the ExpServer project, shown in Wiki article : Project Structure. On the client side, the communication package is responsible for registering the client at the server and for defining communication paths, depending on the type of message being sent. For instance, to establish a connection, the client uses the server IP address, which is then used to transmit necessary client information (i.e., client name and address) to the server. At any time during an experiment, both the client and the server can send and receive three types of messages, to (1) display new screens (i.e., new interactive fragments which are essentially JPanel objects) on the client, (2) request or receive status and logging information, or (3) to add triggers on sensor data upon user actions in an experiment. The message sender (whether it is the client or the server) directly submits serialized messages of one or more of the above types via Java Remote Method Invocation (Java RMI) to the recipient’s incoming message queue, where the message is stored and processed depending on its type. Further, these messages may be addressed to a subset or to all clients. Hence, to ensure the continuity of the ongoing experiment, all messaging traffic is handled asynchronously by a message queue system on the recipient side. In addition to predefined message classes, such as classes for client status information, logging entries, and physiological data, each screen of an experiment can derive its dedicated message class with values specific to the screen (e.g., buy/sell information, bids placed, offers made, and prices). This allows the experimenter to exchange nearly any information between clients and server at any given point in an experiment. We next move on to the next tier, the customizable experimental tier that lets the experimenter to create his/her experiments.
Customizable Experimental Tier
The customizable experimental tier is a separate Java project (Exp_Implementation) that facilitates implementation of new experiments. Each experiment thus consists of a client and a server side, with the former implementing client screens, and the latter consisting of an implementation of the Institution and Environment classes as described earlier. Client screens can be developed using Java Swing, thus enabling access to the extensive UI capabilities and support that Java provides. This aspect of the architecture also facilitates portability to be used on any device that supports Java. For instance, controlled laboratory experiments of specific websites could be run by integrating the BrowserObject in a Java Applet. The platform is distributed with a working demonstration of a Browser Experiment.
Customizable Biosensor Tier
The sensor management and the live-biofeedback layer form a part of the customizable biosensor tier. The sensor management layer facilitates the setting up, connection of, and recording of sensor data via the experimental platform. Currently, implementations for recording ECG, EDA, and EEG data are included. In addition, using Brownie, it is possible to facilitate recording of biosensor data, depending on the individual requirement of the experiment. Hence, it is possible to customize Brownie to use upcoming sensor technologies, for experiments. Also, the biosensor tier contains a live-biofeedback module, integrating the sensor-analysis framework, xAffect and performs real-time monitoring and analysis of heart rate or skin conductance data. The platform hence facilitates the implementation of new real-time monitoring and analysis methods (i.e., processor algorithms) as well as integrating existing live-biofeedback libraries for experiments.
References:
Updated